Norwegian University of Science and Technology
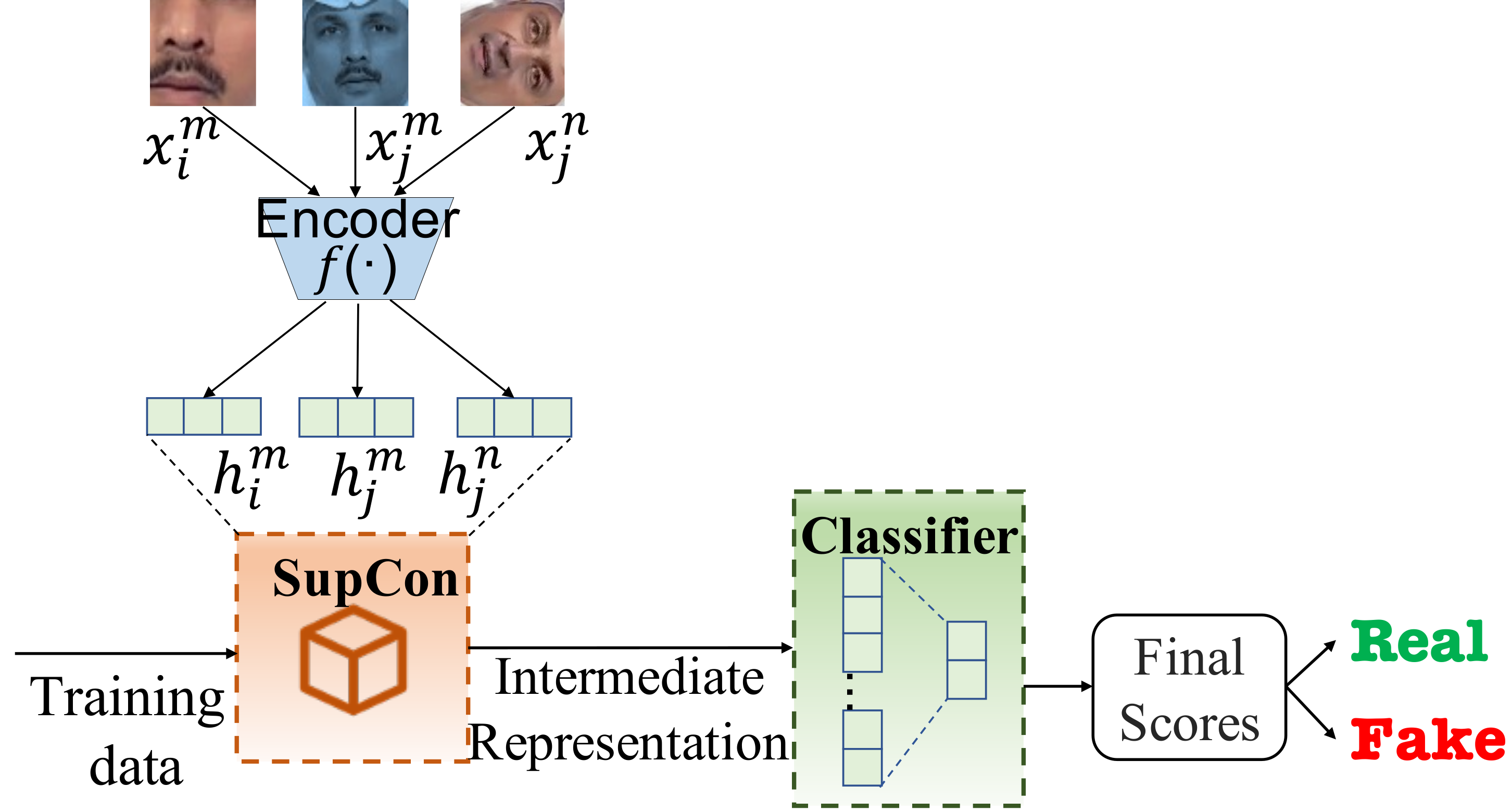
We propose a generalizable detection model that can detect novel and unknown/unseen DeepFakes using a supervised contrastive (SupCon) loss. As DeepFakes can resemble the original image/video to a greater extent in terms of appearance and it becomes challenging to secern them, we propose to exploit the contrasts in the representation space to learn a generalizable detector. We further investigate the features learnt from our proposed approach for explainability. The analysis for explainability of the models advocates the need for fusion and motivated by this, we fuse the scores from the proposed SupCon model and the Xception network to exploit the variability from different architectures. The proposed model consistently performs better compared to the single model on both known data and unknown attacks consistently in a seen data setting and an unseen data setting, with generalizability and explainability as a basis. We obtain the highest accuracy of 78.74% using proposed SupCon model and an accuracy of 83.99% with proposed fusion in a true open-set evaluation scenario where the test class is unknown at the training phase.
Proposed SupCon Model
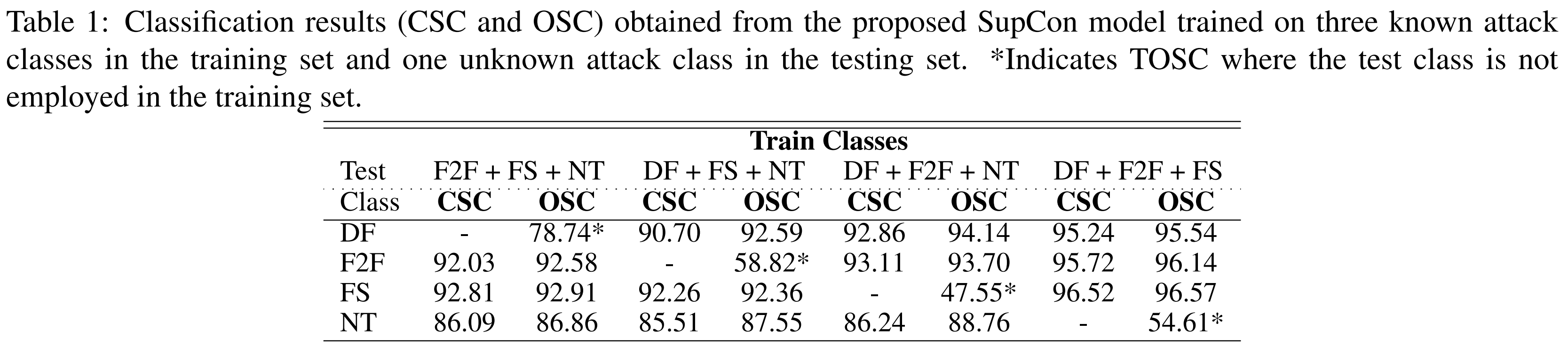
We first present the baseline results of closed-set classification in Table 1, along with the open set classification accuracy to empirically validate the proposed approach of SupCon for DeepFakes detection.
Fusion Model
As the scores may be ideal for different tasks due to the nature of learning and to maximally use the scores from each network, we propose to employ a weighted fusion of the final score from the last activation layer. The architecture of our proposed fusion for DeepFakes detection is presented in Figure below.
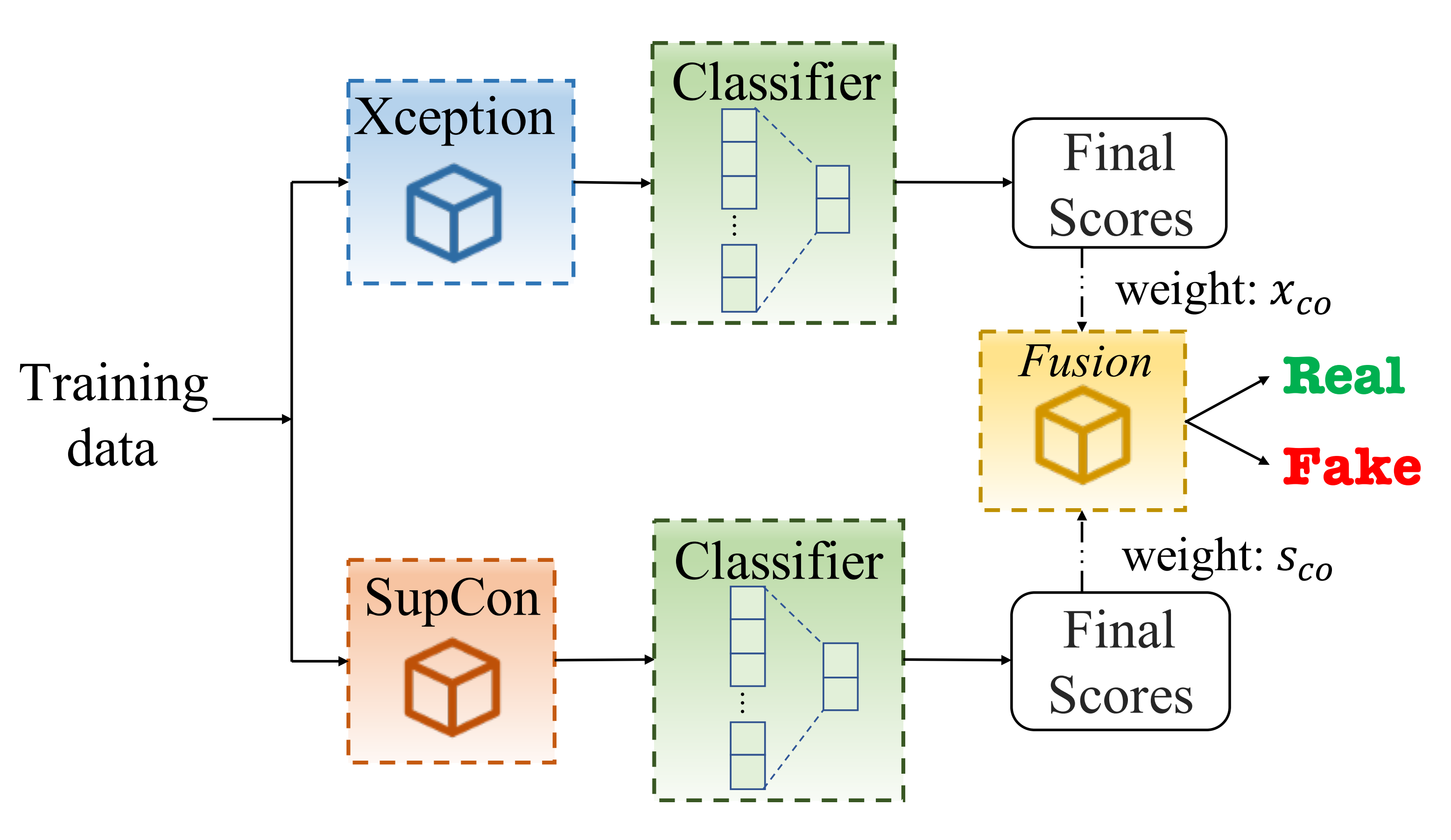
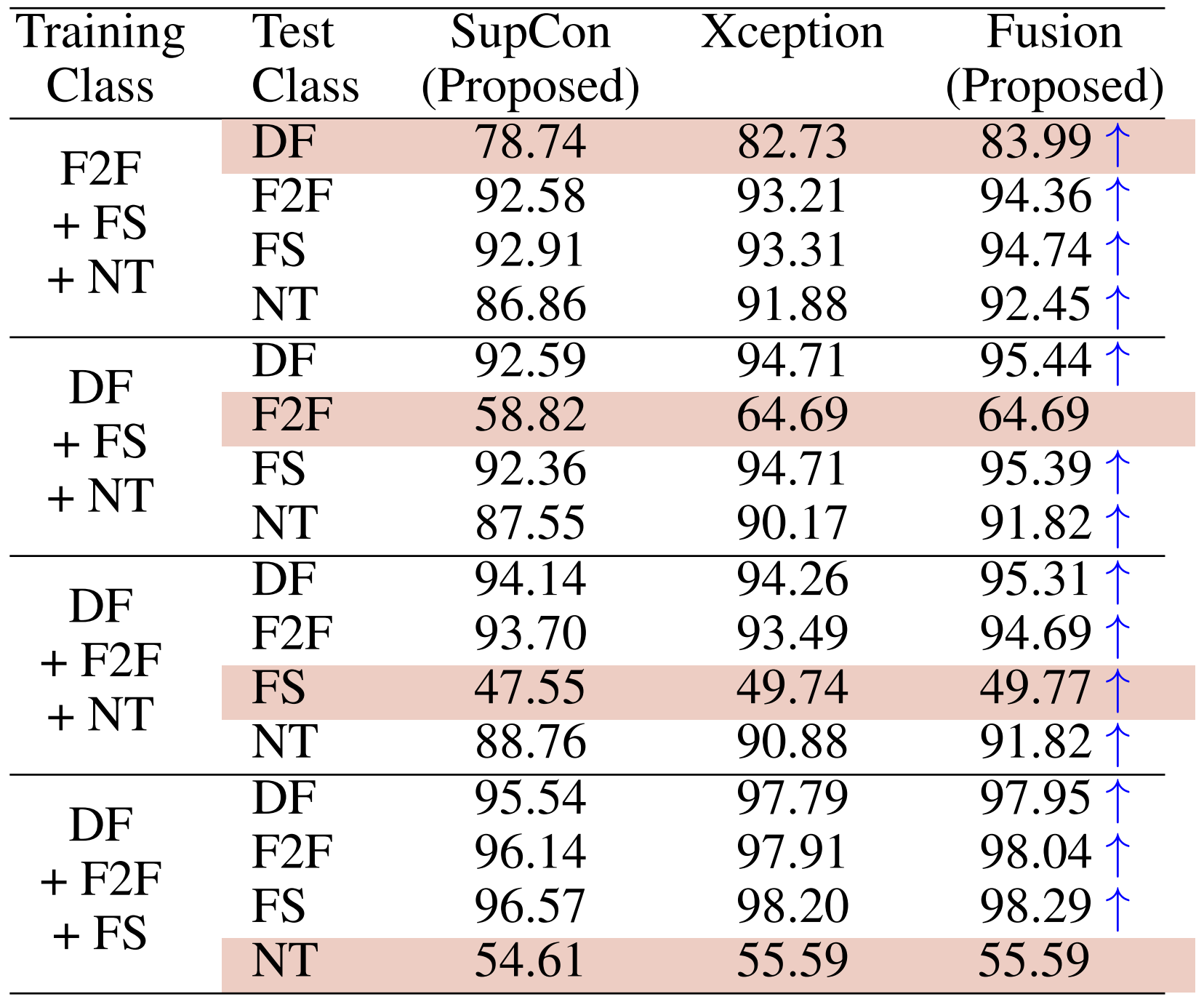
Table below presents the results obtained from the proposed fusion approach in comparison to the proposed SupCon model and Xception model. As it can be noted, our fusion model consistently performs better than a single model, while reaching at-least the lower bound of the performance of Xception model in three cases (not accompanying ↑). The obtained results with a consistent gain indicate the complementarity of our proposed approach in improving the generalizability.
Activation Maps Visualization
Figure below presents the heatmaps corresponding to the last layer of the proposed SupCon overlaid with different kinds of DeepFakes (DF, F2F, FS, and NT). We note that the SupCon focuses on the silhouette on the face region where the manipulation exists. Our assertion of the SupCon applicable to DeepFakes detection is corroborated through visual analysis. We also do a similar analysis on the Xception network as presented in Figure below. Noting from the visual analysis, it is evident that the Xception network focuses on the regions inside the face region such as foreheads, eyebrows, and eyes. The focus of heatmaps on different areas of the face region clearly suggests the complementarity of the networks.

Heatmap for visualization of feature importance comparison from proposed Xception(top) and SupCon(bottom) mode.