Norwegian University of Science and Technology
* Equal contribution
1. Deepfake Dataset Annotations
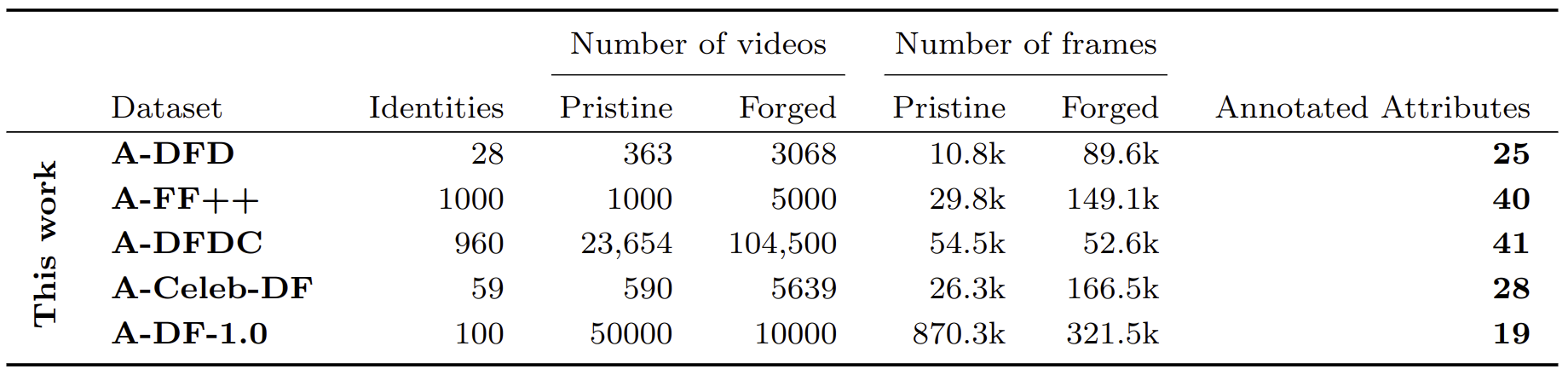
We provide massive and diverse annotations for five widely-used Deepfake detection datasets. Existing Deepfake detection datasets contain none or only sparse annotations restricted to demographic attributes, as shown in Table II. This work provides over 65.3M labels using 47 different attributes for five popular Deepfake detection datasets (Celeb-DF), DeepFakeDetection (DFD), FaceForensics++ (FF++), DeeperForensics-1.0 (DF1.0) and Deepfake Detection Challenge Dataset (DFDC)].
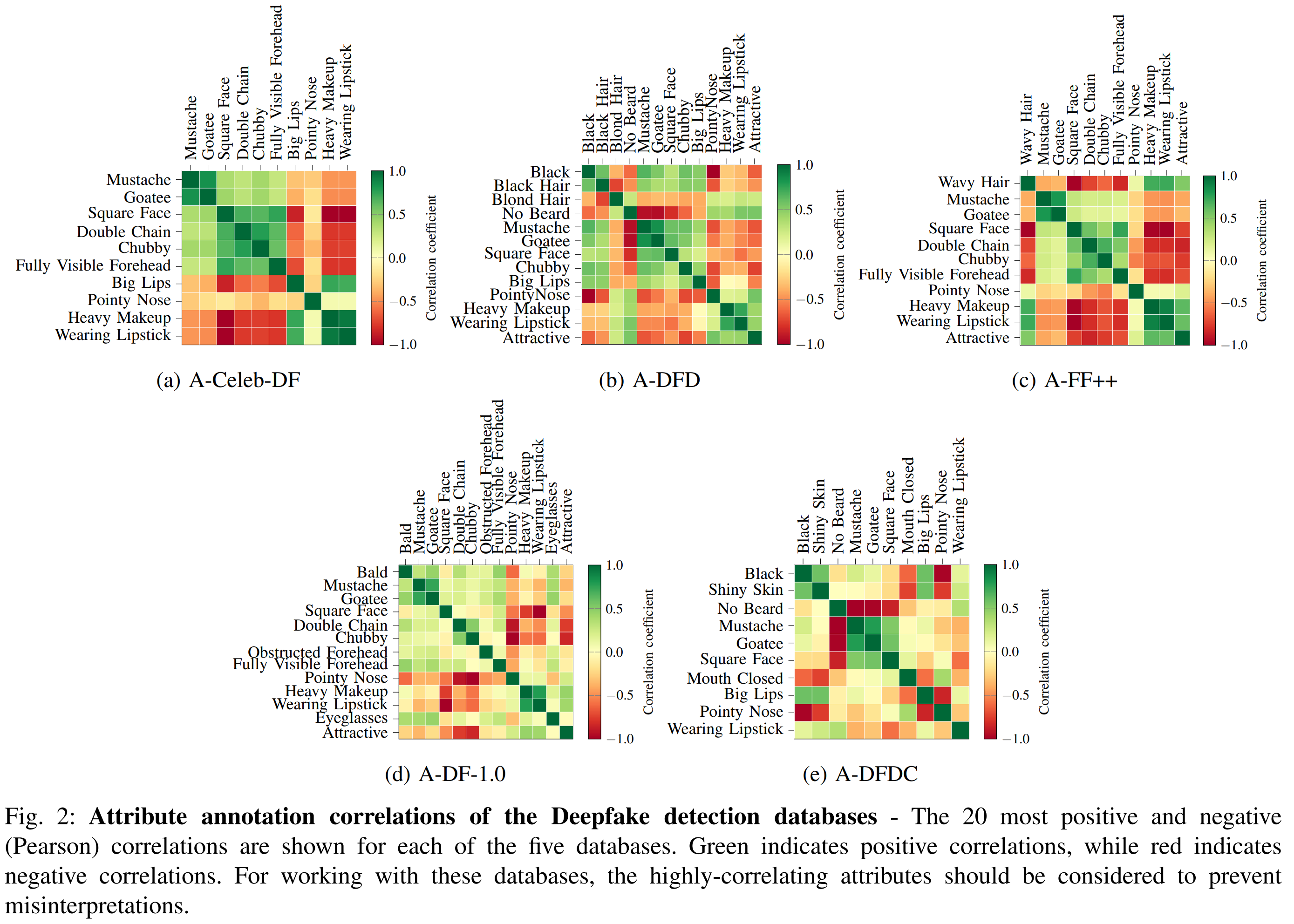
2. Analysing Database Annotations
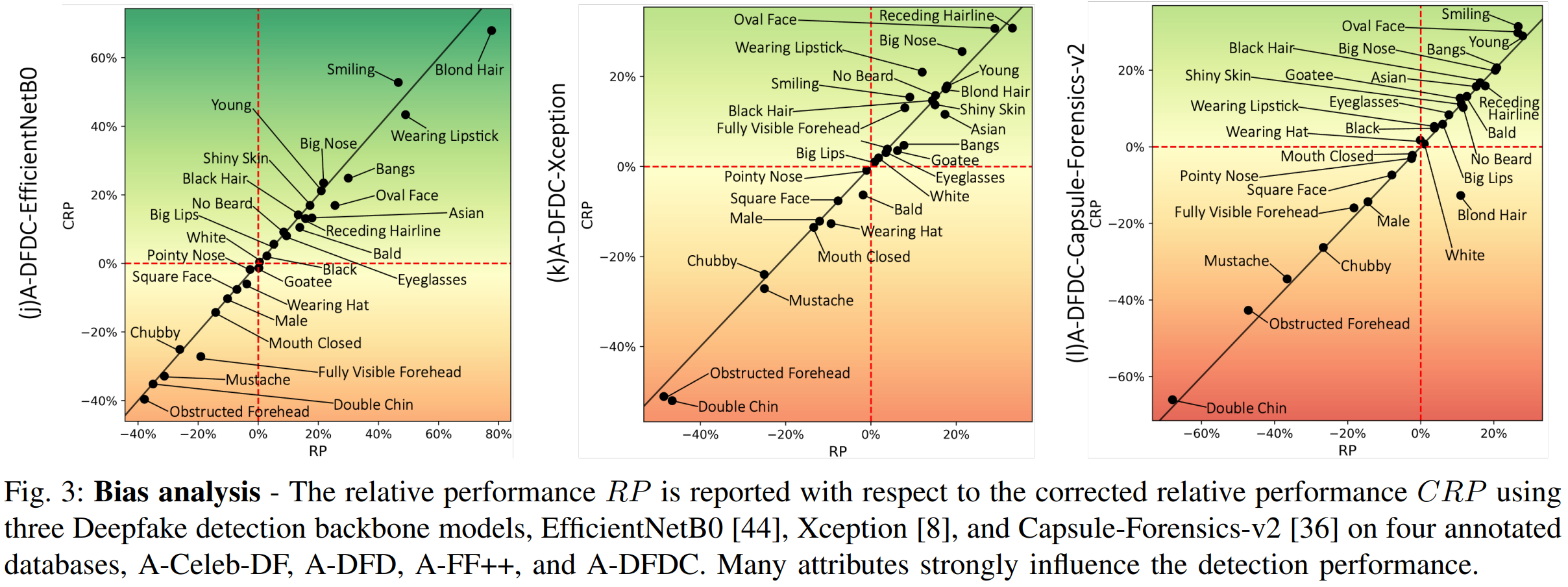
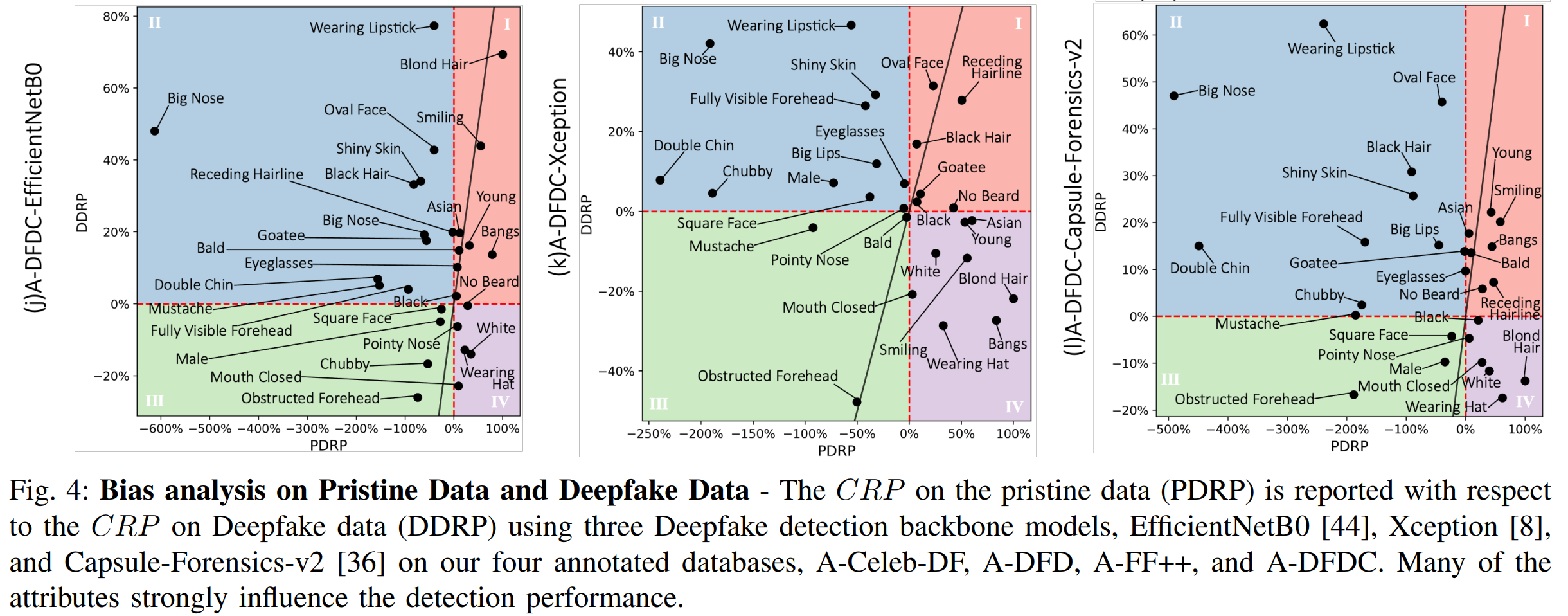
3. Analysing Bias in Deepfake Detection
We comprehensively analyse detection bias in three state-of-the-art Deepfake detection backbone models(Efficient-B0, Xception, Capsule-Forensics-v2 ) with respect to various demographic and non-demographic attributes regarding to four current Deepfake datasets. Previous investigations restricted their analysis to a maximum of four demographic attributes on a single dataset. Contrarily, we analyse detection bias on a much larger scale of distinctive attributes on four widely-used Deepfake datasets2.